今天分享一篇来自ISSTA 2022 的论文 “An Empirical Study on the Effectiveness of Static C Code Analyzers for Vulnerability Detection”
Introduction
静态代码分析技术在现有的projects中已经有较广泛的使用率,77%的项目都会应用至少一种analyzer。相比于动态的模糊测试,静态代码分析的速度更快,而且使用更为容易。fuzz一般需要跑数小时才能找到crash,而静态分析往往一小时内就可以找到代码可能存在的bug。但是fuzz由于是运行时的测试,因此不会有误报。而静态分析产生的bug的正确率则往往不够理想
现有的对于代码静态分析器效率的研究工作大多是基于人工合成漏洞的benchmark,而他们的篡改方式往往是要么由所谓的bug注入引擎自动完成,例如在LAVA - M数据集,要么手动完成,例如在Juliet Test Suite 数据集中。
这些插入的代码篡改语法是比较容易被发现的,因此这些研究工作能报告出来的准确率有80%左右,对于一些特定类型的bug甚至能做到100%检测到。
但问题就在于这不符合现实场景。
于是作者提出基于CVE报告自动评估静态代码分析器有效性,并且检验由此发现的漏洞的真实性。
并且还做了一项工作是分析了单个分析器vs多个分析器一起使用时bug检测和被标记函数数量的变化。
Static Code Analysis
作者选择了两种方法,句法静态分析(Syntactic Static Analysis)和 语义静态分析(Semantic Static Analysis)
Analyzer选择的是Flawfinder (FLF),Cppcheck (CPC),Infer (IFR),CodeChecker (CCH),CodeQL (CQL),CommSCA (CSA) 这六个。
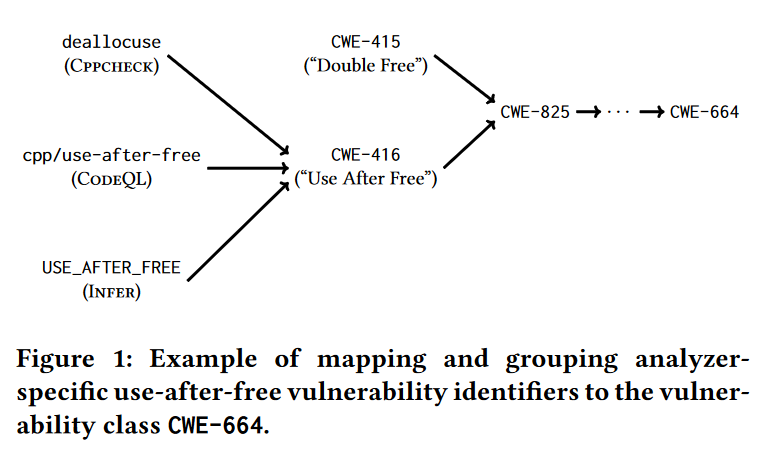
然后将CWE按照它们的描述(对应的漏洞类别)进行parent-children模式的归纳
将CWE归纳之后,由于不同分析器对于相同CWE的identifier不同,于是还创建了identifier->CWE的映射,即下图左侧的箭头。
Benchmarking
作者想要挑选的数据集是real-world含有漏洞(CVE)的项目,但现实中这样的数据集很少。于是作者选用了一个叫
Magma的数据集,这是一个由验证的CVE报告构建的基准数据集,最初是为了评估模糊测试的有效性而设计的。所包含的程序包含了大量且多样化的漏洞,这些漏洞也应该被静态C分析器检测到。Magma因此使用了一种名为前端移植( front-porting )的技术,将过去发现并公开报告的安全漏洞重新插入到最新的程序版本中。对于每一个移植的漏洞,Magma都会指定-除了根本原因-它所表现的、可能导致程序崩溃的函数。Magma当中含有111个漏洞。
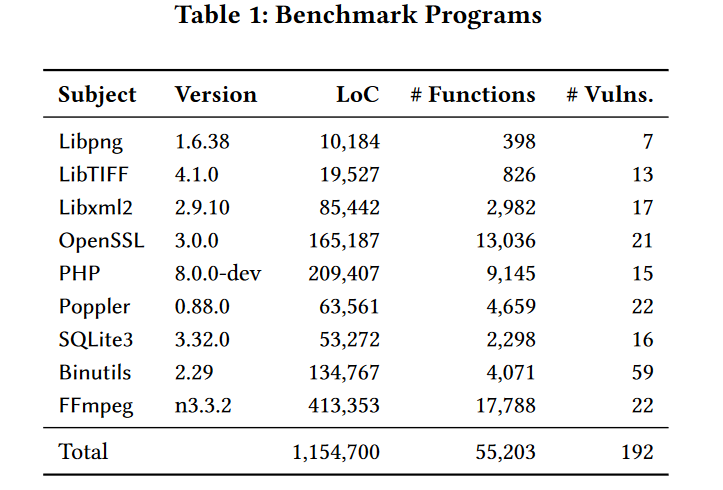
除了magma,作者还用到了一个叫Binutils suite的数据集,这个数据集包括19个用于操作编译代码的程序和视频/音频处理工具FFmpeg,如Table1和Figure2所示:
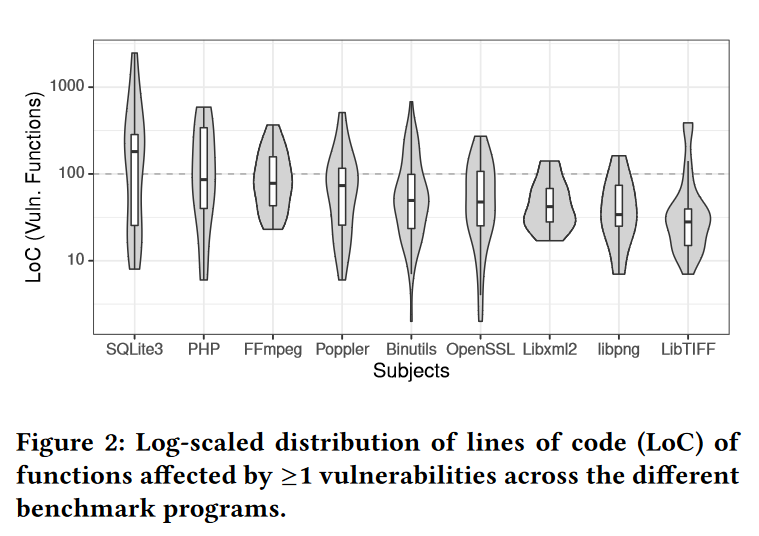
上图Figure2的展示方式是以对数刻度来表示的代码行数(Lines of Code,LoC)分布情况,这些代码行受到一个或多个漏洞所影响,同时这些代码来自不同的benchmark
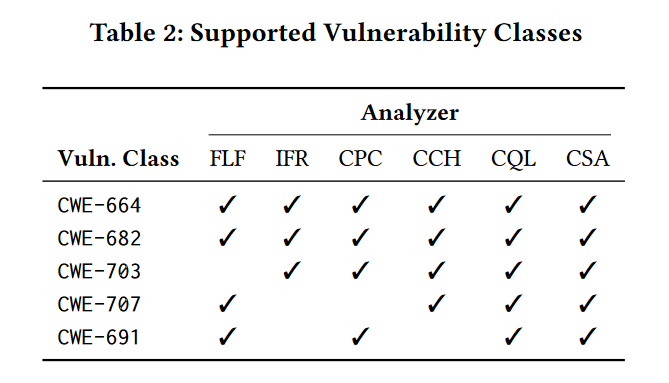
Table2给出了每个漏洞类别是否由各自的静态分析器支持(√),或者不支持(空白)的情况。因此,如果文档声明各自的分析器对该特定类中的至少一种漏洞类型执行安全检查,则认为该类是被支持的(因为前面有对漏洞做分类与配对操作):
在代码粒度方面,作者选择了使用function-level,因为如果细化到代码行或者基本的代码块,就会需要手动决定很多指令是否为漏洞的表现(manifestation)。
提到漏洞的表现(manifestation)和根本原因(root cause),一般来说现在的静态分析器标记的是在执行过程中,漏洞可能表现为安全关键的程序状态(错误)代码的位置,而不是相应根本原因(错误)的位置。这样做的原因之一是为了减少误报的数量,因为并不是每一个错误都必然表现为一个安全缺陷。因此,漏洞的错误可能发生在代码中与故障不同的地方。Figure 4给出了这个问题的一个例子:

其中第三行是root cause,第六行及其后的一些代码是manifestation,作者测试的所有分析器都没有将漏洞标记在第三行,而是在后面的第6、18、19行各自标记了一些CWE。
作者也将root cause称作fault,将manifestation称作error
fault和error可能被识别在不同的function中,为了证明这点,作者规定了一个标准:FEC
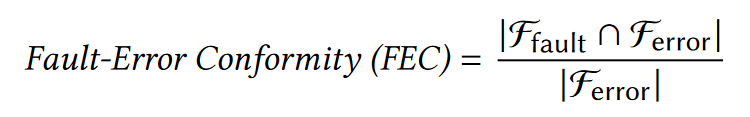
对于给定的CVE ,计算包含error的函数的比率(Ferror) ,其中也包括潜在的fault( Ffault )。
FEC比率越高,给定CVE的fault和error出现在同一function内的概率越高。
下表展示了magma含有的项目的FEC
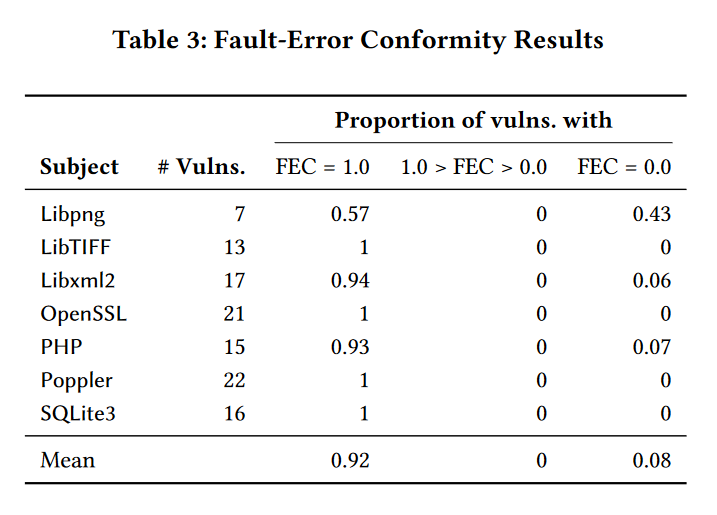
得出结论是:在magma中得到的结果是92 %的Magma CVE,error和manifestation都位于相同的函数中。因此function-level是一个合适的代码抽象,可以使用基于CVE的基准数据集来评估这些工具的有效性。
Evaluation Setup
本次研究主要围绕以下三个问题展开
RQ1、最state-of-art的静态C代码分析器在检测真实世界代码库中的漏洞时的效率?
RQ2、静态C代码分析器在合并使用时的效率vs最强大的单个分析器使用时的效率
RQ3、静态C代码分析器对哪几类漏洞检测效果最好/最坏
定义了两个metric:
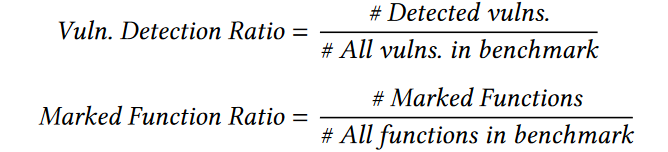
这两个metric都很好理解。
然后从四个评估场景(Evaluation Scenarios)来查看漏洞是否被检测
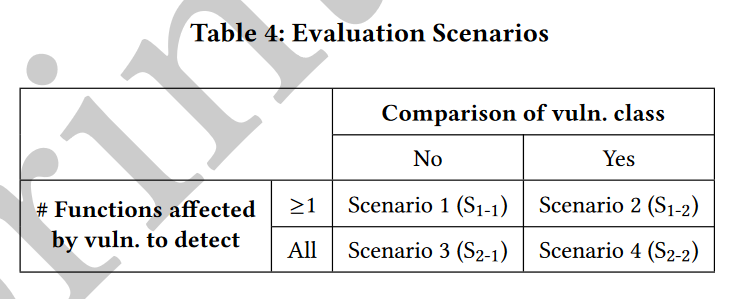
S1-1:至少一个漏洞被标记,则认为检测到了漏洞,regardless of 是否符合公布的漏洞的类别(有时候我觉得像regardless of这样的短语保留其英语原话能更好理解)
S1-2:至少一个漏洞被标记,并且与公布的漏洞的类别相同,则认为检测到了漏洞。
S2-1:所有漏洞被标记,regardless of 是否符合公布的漏洞的类别
S2-2:所有漏洞被标记,并与公布的漏洞类别相同
在正式开始跑数据之前,作者还做了一些预备工作,比如查阅分析器的文档,把分析器中一些默认关闭的但是需要用来检测现有漏洞的checker打开;把一些默认开着的但不用于本次检测的checker关闭(比如code smell或者unreachable codes等)
(ps. 在论文中,“code smell”(代码异味)是指源代码中存在的潜在问题或不良实践的迹象。它是一种主观的判断,用于描述代码中表现出的质量问题。代码异味可能是因为设计缺陷、不一致的命名、冗长的代码、重复代码、复杂的逻辑、过度耦合等原因导致的。它们并不是编译错误或语法错误,而是对代码结构、可读性、可维护性和扩展性产生负面影响的指标。)
Evaluation Results
接着就直接来看结果吧
RQ1:Static Analyzer Effectiveness
从项目的角度来看
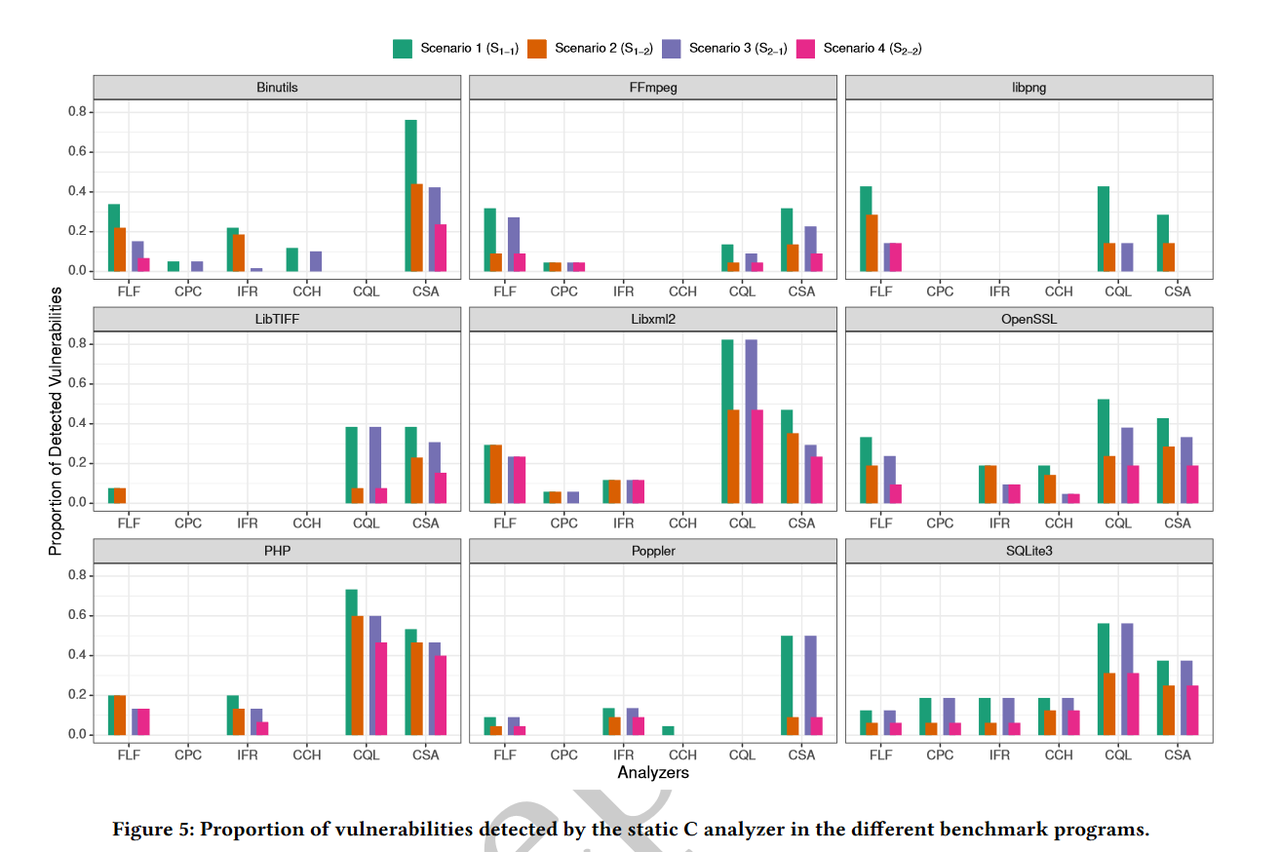
可见许多漏洞不能被所选的静态分析器发现。在Poppler、FFmpeg和Libpng中,分析仪表现特别差,作者猜测可能是由于以下原因:Poppler,它是benchmark中唯一的C++程序。虽然所有使用的工具都支持C / C++,但它们似乎主要集中在纯C上,对C++只提供了初步的支持。至于FFmpeg,它是我们benchmark中最大的程序,有413353行代码,当if或# ifdef语句的嵌套深度达到一定的限制时,它可能会迫使静态分析器中止分析。对于Libpng,检测率较低的原因可能是其部分漏洞的故障和错误函数不同。
从分析器的角度来看:
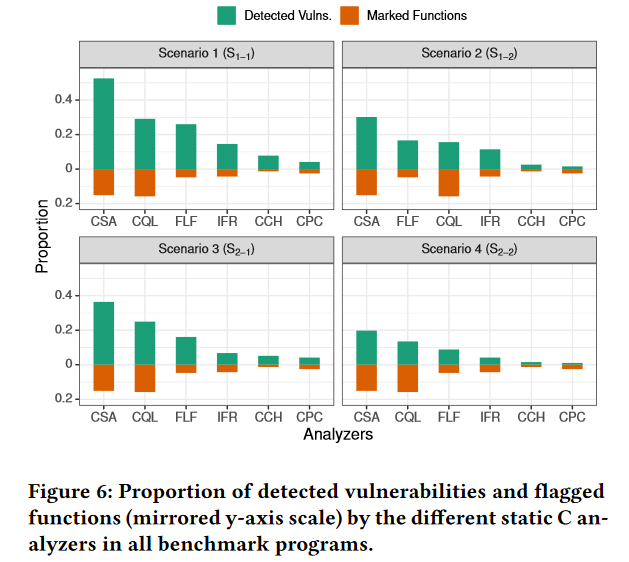
其中效果最好的是Comm SCA、CodeQL和Flawfinder,而Cppcheck、CodeChecker和Infer是检测到的漏洞最少的。商用分析器Comm SCA在所有评估场景中都优于次优的免费开源静态分析器,即:分别用CodeQL . Flawfinder通过45 ( 24%),发现了26个( 13% )、22个( 11%)和12个( 6% )更多的安全漏洞。Comm SCA因此标记的功能比CodeQL略少,因此可能返回更少的误报。有趣的是,在标记函数数量大致相同的情况下,Flawfinder在四种场景下的表现均优于Infer。此外,它在S1-1、S1-2中具有与CodeQL大致相同的检测率,而标记少了11%的函数。这说明语义分析方法并不总是比不太复杂的句法分析方法更有效
实证评估表明,最先进的静态C代码分析器忽略了大量真实世界的漏洞。根据评估场景的不同,即使是性能最高的分析器( Comm SCA )也无法检测出基准数据集中192个漏洞中的47 % ( S1-1 )、70 % ( S1-2 )、64 % ( S2-1 )和80 % ( S2-2 )。
RQ2:Effectiveness Increase by Analyzer Combinations
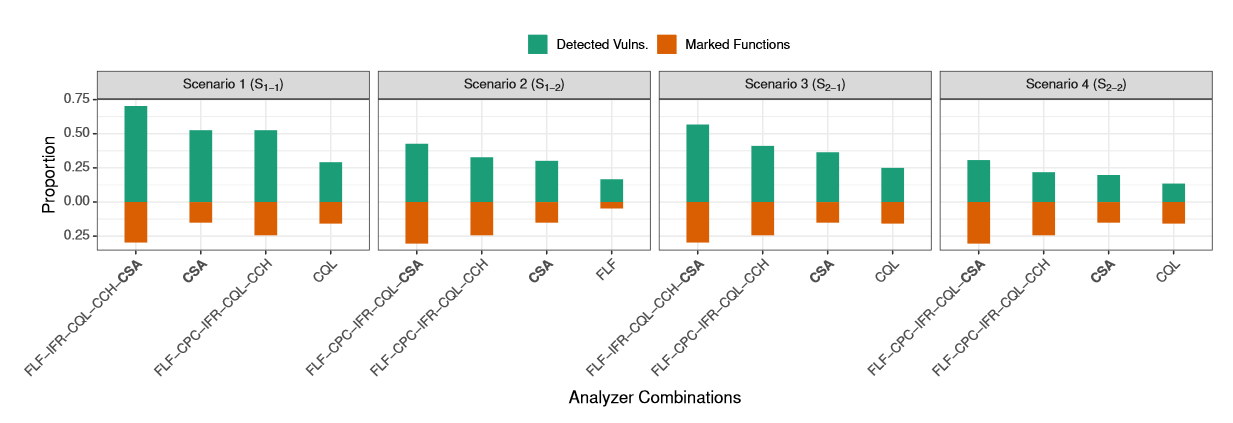
实证评估表明,使用多个静态C代码分析器可以在不同的评估场景中比单个性能最好的分析器提高21 ~ 34个百分点的漏洞检测,同时将15%以上的功能标记为潜在的漏洞。尽管如此,最佳组合仍然遗漏了192个漏洞中的30 % ( S1-1 )、57 % ( S1-2 )、43 % ( S2-1 )和69 % ( S2-2 )。
RQ3: Best vs. Worst Detected Vulnerabilities
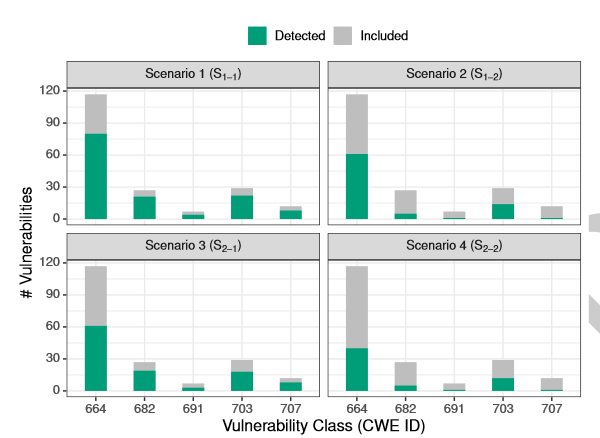
实证评估表明,静态C代码分析器对CWE - { 664,703 }类的漏洞检测比对CWE - { 682,707,691 }类的漏洞检测更有效。然而,根据评估场景的不同,117个CWE - 664漏洞中有32 % - 66 %被工具遗漏,29个CWE - 703漏洞中有24 % - 59 %被工具遗漏。
至此这篇文章的分析我们就写到这里。
Summary
这篇文章的主题是对于静态分析工具效率的实证性研究,但是不同静态分析工具使用的技术范围很广,因此缺少一种客观评估它们的有效性的方法。
作者首先提出现有的(指2022年)静态分析工具的局限,主要有两点:
1、使用人工合成的数据集,这些数据集的漏洞并不能反映实际中发现的安全漏洞的复杂性;
2、没有针对静态分析器输出的漏洞类型进行差异化分析。因此,他们关于分析器检测漏洞能力的结论可能无法推广到真实程序中。
作者提出了一种基于CVE报告自动评估静态代码分析器有效性的方法。他们评估了5个免费开源的和1个商用的静态C代码分析器,针对27个软件项目,共包含115万行代码和192个漏洞。虽然静态C分析器已经被证明在具有合成bug的benchmark(人为添加bug用于测试的程序)中表现良好,但在一个真实程序的benchmark中,最state-of-art的分析工具都遗漏了47%到80%的漏洞。如果结合静态分析工具的结果,可以将漏报率降低到30%~69%,多标记15%的函数。
论文地址:https://doi.org/10.1145/3533767.3534380
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !