INTERNAL_SIZE_T mchunk_prev_size; /* Size of previous chunk (if free). */ INTERNAL_SIZE_T mchunk_size; /* Size in bytes, including overhead. */
structmalloc_chunk* fd;/* double links -- used only if free. */ structmalloc_chunk* bk;
/* Only used for large blocks: pointer to next larger size. */ structmalloc_chunk* fd_nextsize;/* double links -- used only if free. */ structmalloc_chunk* bk_nextsize; };
/* size field is or'ed with NON_MAIN_ARENA if the chunk was obtained from a non-main arena. This is only set immediately before handing the chunk to the user, if necessary. */ #define NON_MAIN_ARENA 0x4
/* Bits to mask off when extracting size Note: IS_MMAPPED is intentionally not masked off from size field in macros for which mmapped chunks should never be seen. This should cause helpful core dumps to occur if it is tried by accident by people extending or adapting this malloc. */ #define SIZE_BITS (PREV_INUSE | IS_MMAPPED | NON_MAIN_ARENA)
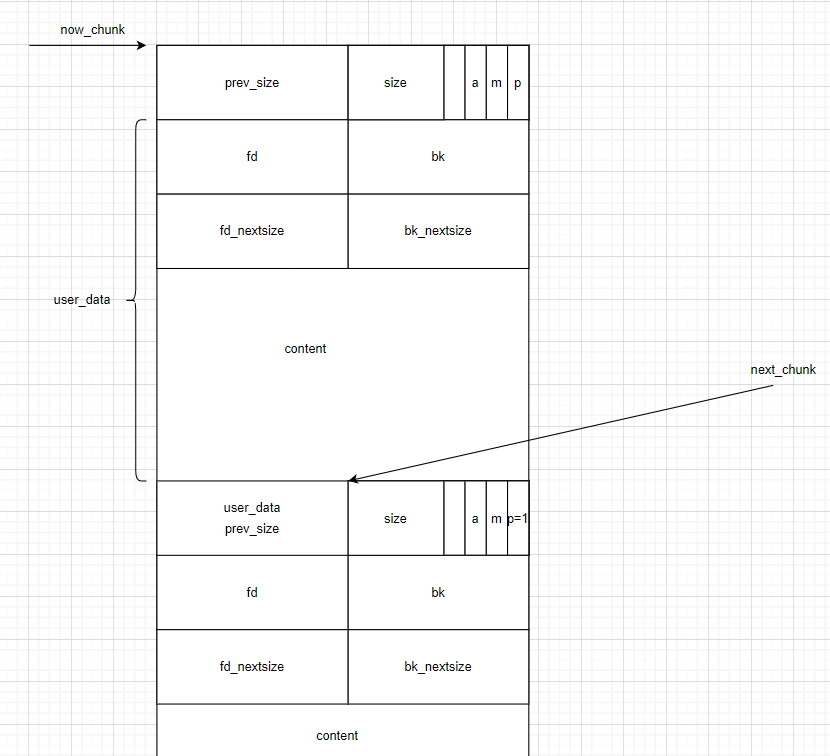
/* malloc_chunk details: (The following includes lightly edited explanations by Colin Plumb.) Chunks of memory are maintained using a `boundary tag' method as described in e.g., Knuth or Standish. (See the paper by Paul Wilson ftp://ftp.cs.utexas.edu/pub/garbage/allocsrv.ps for a survey of such techniques.) Sizes of free chunks are stored both in the front of each chunk and at the end. This makes consolidating fragmented chunks into bigger chunks very fast. The size fields also hold bits representing whether chunks are free or in use. An allocated chunk looks like this: chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk, if unallocated (P clear) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of chunk, in bytes |A|M|P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | User data starts here... . . . . (malloc_usable_size() bytes) . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | (size of chunk, but used for application data) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of next chunk, in bytes |A|0|1| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ Where "chunk" is the front of the chunk for the purpose of most of the malloc code, but "mem" is the pointer that is returned to the user. "Nextchunk" is the beginning of the next contiguous chunk. Chunks always begin on even word boundaries, so the mem portion (which is returned to the user) is also on an even word boundary, and thus at least double-word aligned. Free chunks are stored in circular doubly-linked lists, and look like this: chunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of previous chunk, if unallocated (P clear) | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `head:' | Size of chunk, in bytes |A|0|P| mem-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Forward pointer to next chunk in list | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Back pointer to previous chunk in list | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Unused space (may be 0 bytes long) . . . . | nextchunk-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ `foot:' | Size of chunk, in bytes | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Size of next chunk, in bytes |A|0|0| +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ The P (PREV_INUSE) bit, stored in the unused low-order bit of the chunk size (which is always a multiple of two words), is an in-use bit for the *previous* chunk. If that bit is *clear*, then the word before the current chunk size contains the previous chunk size, and can be used to find the front of the previous chunk. The very first chunk allocated always has this bit set, preventing access to non-existent (or non-owned) memory. If prev_inuse is set for any given chunk, then you CANNOT determine the size of the previous chunk, and might even get a memory addressing fault when trying to do so. The A (NON_MAIN_ARENA) bit is cleared for chunks on the initial, main arena, described by the main_arena variable. When additional threads are spawned, each thread receives its own arena (up to a configurable limit, after which arenas are reused for multiple threads), and the chunks in these arenas have the A bit set. To find the arena for a chunk on such a non-main arena, heap_for_ptr performs a bit mask operation and indirection through the ar_ptr member of the per-heap header heap_info (see arena.c). Note that the `foot' of the current chunk is actually represented as the prev_size of the NEXT chunk. This makes it easier to deal with alignments etc but can be very confusing when trying to extend or adapt this code. The three exceptions to all this are: 1. The special chunk `top' doesn't bother using the trailing size field since there is no next contiguous chunk that would have to index off it. After initialization, `top' is forced to always exist. If it would become less than MINSIZE bytes long, it is replenished. 2. Chunks allocated via mmap, which have the second-lowest-order bit M (IS_MMAPPED) set in their size fields. Because they are allocated one-by-one, each must contain its own trailing size field. If the M bit is set, the other bits are ignored (because mmapped chunks are neither in an arena, nor adjacent to a freed chunk). The M bit is also used for chunks which originally came from a dumped heap via malloc_set_state in hooks.c. 3. Chunks in fastbins are treated as allocated chunks from the point of view of the chunk allocator. They are consolidated with their neighbors only in bulk, in malloc_consolidate. */
/* ---------- Size and alignment checks and conversions ---------- */
/* Conversion from malloc headers to user pointers, and back. When using memory tagging the user data and the malloc data structure headers have distinct tags. Converting fully from one to the other involves extracting the tag at the other address and creating a suitable pointer using it. That can be quite expensive. There are cases when the pointers are not dereferenced (for example only used for alignment check) so the tags are not relevant, and there are cases when user data is not tagged distinctly from malloc headers (user data is untagged because tagging is done late in malloc and early in free). User memory tagging across internal interfaces: sysmalloc: Returns untagged memory. _int_malloc: Returns untagged memory. _int_free: Takes untagged memory. _int_memalign: Returns untagged memory. _int_memalign: Returns untagged memory. _mid_memalign: Returns tagged memory. _int_realloc: Takes and returns tagged memory. */
/* Set if the fastbin chunks contain recently inserted free blocks. */ /* Note this is a bool but not all targets support atomics on booleans. */ int have_fastchunks;
/* Fastbins */ mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */ mchunkptr top;
/* The remainder from the most recent split of a small request */ mchunkptr last_remainder;
/* Normal bins packed as described above */ mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */ unsignedint binmap[BINMAPSIZE];
/* Linked list */ structmalloc_state *next;
/* Linked list for free arenas. Access to this field is serialized by free_list_lock in arena.c. */ structmalloc_state *next_free;
/* Number of threads attached to this arena. 0 if the arena is on the free list. Access to this field is serialized by free_list_lock in arena.c. */ INTERNAL_SIZE_T attached_threads;
/* Memory allocated from the system in this arena. */ INTERNAL_SIZE_T system_mem; INTERNAL_SIZE_T max_system_mem; };
以上源码中,flags标志位用来表示当前arena中是否存在fastbin或者内存是否连续等,暂且不去管他
后面定义的是一些比较重要的结构,可以看到主要有两个数组fastbinsY[]和bins[],fastbinsY的数量是NFASTBINS根据宏定义得知也就是10个
而bins数组中的第一个 bin 是 unsorted bin(1个),数组中从第 2 个到第 63 个 bin 是 small bin(62个),64到126为large bin(63个)
看到这里会产生疑惑,我们在寻找宏定义的时候看到NBINS是128,而bins的数量是NBINS*2-2也就是254,那为什么上述bins加起来也只有一半不到呢?
答案就是unsorted bin, small bin, large bin三者都是由双向链表构成,需要数组中两个相邻的值表示一个chunk。
所以这样表述可能会更贴切:bins中每一组数据由两个元素组成,第1组是Unsorted bin,第2 到 63组是Small bin,第64 到 126组是Large bin。 binmap这个数组表示每一个bit表示对应的bin中是否存在空闲chunk
/* Indexing Bins for sizes < 512 bytes contain chunks of all the same size, spaced 8 bytes apart. Larger bins are approximately logarithmically spaced: 64 bins of size 8 32 bins of size 64 16 bins of size 512 8 bins of size 4096 4 bins of size 32768 2 bins of size 262144 1 bin of size what's left There is actually a little bit of slop in the numbers in bin_index for the sake of speed. This makes no difference elsewhere. The bins top out around 1MB because we expect to service large requests via mmap. Bin 0 does not exist. Bin 1 is the unordered list; if that would be a valid chunk size the small bins are bumped up one. */
small bin:根据用户请求的 sz 大小得到 small bin的下标的方法是:chunk_size = MALLOC_ALIGNMENT * indx,其中 MALLOC_ALIGNMENT = 2 * SIZE_SZ。所以对于 32位,最大 chunk 为 504字节,对于64最大为 1008 字节。
large bin:共包含 63 个 bin,每个 bin 中的chunk 大小不一致,而是在一定范围之内,63个 bin 被分成 6 组,每组 Bin 的 chunk 的大小之间的公差一致。
largebin 排列方式从大到小依次排列,链表头的 bk 指针指向最小的堆块.
unsorted bin和small bin采取FIFO(first in first out),其余是FILO
_heap_info
1 2 3 4 5 6 7 8 9 10 11 12 13
typedefstruct _heap_info { mstate ar_ptr; /* Arena for this heap. */ struct _heap_info *prev;/* Previous heap. */ size_t size; /* Current size in bytes. */ size_t mprotect_size; /* Size in bytes that has been mprotected PROT_READ|PROT_WRITE. */ size_t pagesize; /* Page size used when allocating the arena. */ /* Make sure the following data is properly aligned, particularly that sizeof (heap_info) + 2 * SIZE_SZ is a multiple of MALLOC_ALIGNMENT. */ char pad[-3 * SIZE_SZ & MALLOC_ALIGN_MASK]; } heap_info;
#if USE_TCACHE /* int_free also calls request2size, be careful to not pad twice. */ size_t tbytes; if (!checked_request2size (bytes, &tbytes)) { __set_errno (ENOMEM); returnNULL; } size_t tc_idx = csize2tidx (tbytes);
if (ar_ptr != NULL) __libc_lock_unlock (ar_ptr->mutex);
/* In a low memory situation, we may not be able to allocate memory - in which case, we just keep trying later. However, we typically do this very early, so either there is sufficient memory, or there isn't enough memory to do non-trivial allocations anyway. */ if (victim) { tcache = (tcache_perthread_struct *) victim; memset (tcache, 0, sizeof (tcache_perthread_struct)); } } # define MAYBE_INIT_TCACHE() \ if (__glibc_unlikely (tcache == NULL)) \ tcache_init();
/* Binmap To help compensate for the large number of bins, a one-level index structure is used for bin-by-bin searching. `binmap' is a bitvector recording whether bins are definitely empty so they can be skipped over during during traversals. The bits are NOT always cleared as soon as bins are empty, but instead only when they are noticed to be empty during traversal in malloc. */
/* Conservatively use 32 bits per map word, even if on 64bit system */ #define BINMAPSHIFT 5 #define BITSPERMAP (1U << BINMAPSHIFT) #define BINMAPSIZE (NBINS / BITSPERMAP)
/* Convert request size to internal form by adding SIZE_SZ bytes overhead plus possibly more to obtain necessary alignment and/or to obtain a size of at least MINSIZE, the smallest allocatable size. Also, checked_request2size returns false for request sizes that are so large that they wrap around zero when padded and aligned. */
if (!checked_request2size (bytes, &nb)) { __set_errno (ENOMEM); returnNULL; }
/* There are no usable arenas. Fall back to sysmalloc to get a chunk from mmap. */ if (__glibc_unlikely (av == NULL)) { void *p = sysmalloc (nb, av); if (p != NULL) alloc_perturb (p, bytes); return p; }
在malloc的实现中,需要频繁的插入和删除各个bin中的chunk,很多地方用到了CAS操作,因为用的比较多,这里先简单介绍一下
CAS是compare and swap的缩写,它是原子操作的一种,可用于在多线程编程中实现不被打断的数据交换操作,从而避免多线程同时改写某一数据时由于执行顺序不确定性以及中断的不可预知性产生的数据不一致问题,该操作通过将内存中的值与指定数据进行比较,当数值一样时将内存中的数据替换为新的值。
CAS需要有3个操作数:内存地址,旧的预期值,即将要更新的目标值,CAS指令执行时,当且仅当内存地址的值与预期值相等时,将内存地址的值修改为目标值,否则就什么都不做,整个比较并替换的操作是一个原子操作,下面举一个例子:
if (victim != NULL) { if (__glibc_unlikely (misaligned_chunk (victim))) malloc_printerr ("malloc(): unaligned fastbin chunk detected 2");
if (SINGLE_THREAD_P) *fb = REVEAL_PTR (victim->fd); else REMOVE_FB (fb, pp, victim); if (__glibc_likely (victim != NULL)) { size_t victim_idx = fastbin_index (chunksize (victim)); if (__builtin_expect (victim_idx != idx, 0)) malloc_printerr ("malloc(): memory corruption (fast)"); check_remalloced_chunk (av, victim, nb); ``` 首先判断内部大小是否在fastbin的范围内,与get_max_fast()函数取得的最大大小比较: ```c staticinline INTERNAL_SIZE_T get_max_fast(void) { /* Tell the GCC optimizers that global_max_fast is never larger than MAX_FAST_SIZE. This avoids out-of-bounds array accesses in _int_malloc after constant propagation of the size parameter. (The code never executes because malloc preserves the global_max_fast invariant, but the optimizers may not recognize this.) */ if (global_max_fast > MAX_FAST_SIZE) __builtin_unreachable (); return global_max_fast; }
#if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx (nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = *fb) != NULL) { if (__glibc_unlikely (misaligned_chunk (tc_victim))) malloc_printerr ("malloc(): unaligned fastbin chunk detected 3"); if (SINGLE_THREAD_P) *fb = REVEAL_PTR (tc_victim->fd); else { REMOVE_FB (fb, pp, tc_victim); if (__glibc_unlikely (tc_victim == NULL)) break; } tcache_put (tc_victim, tc_idx); } }
if (in_smallbin_range (nb)) { idx = smallbin_index (nb); bin = bin_at (av, idx);
if ((victim = last (bin)) != bin) { bck = victim->bk; if (__glibc_unlikely (bck->fd != victim)) malloc_printerr ("malloc(): smallbin double linked list corrupted"); set_inuse_bit_at_offset (victim, nb); bin->bk = bck; bck->fd = bin;
if (av != &main_arena) set_non_main_arena (victim); check_malloced_chunk (av, victim, nb); #if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx (nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = last (bin)) != bin) { if (tc_victim != 0) { bck = tc_victim->bk; set_inuse_bit_at_offset (tc_victim, nb); if (av != &main_arena) set_non_main_arena (tc_victim); bin->bk = bck; bck->fd = bin;
#if USE_TCACHE /* While we're here, if we see other chunks of the same size, stash them in the tcache. */ size_t tc_idx = csize2tidx (nb); if (tcache && tc_idx < mp_.tcache_bins) { mchunkptr tc_victim;
/* While bin not empty and tcache not full, copy chunks over. */ while (tcache->counts[tc_idx] < mp_.tcache_count && (tc_victim = last (bin)) != bin) { if (tc_victim != 0) { bck = tc_victim->bk; set_inuse_bit_at_offset (tc_victim, nb); if (av != &main_arena) set_non_main_arena (tc_victim); bin->bk = bck; bck->fd = bin;
前面提到small bin分配的前提是通过small bin size和是否形成双向链表的检查,如果没通过就不会分配,并且运行到这里:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* If this is a large request, consolidate fastbins before continuing. While it might look excessive to kill all fastbins before even seeing if there is space available, this avoids fragmentation problems normally associated with fastbins. Also, in practice, programs tend to have runs of either small or large requests, but less often mixtures, so consolidation is not invoked all that often in most programs. And the programs that it is called frequently in otherwise tend to fragment. */
/* ------------------------- malloc_consolidate ------------------------- malloc_consolidate is a specialized version of free() that tears down chunks held in fastbins. Free itself cannot be used for this purpose since, among other things, it might place chunks back onto fastbins. So, instead, we need to use a minor variant of the same code. */
staticvoidmalloc_consolidate(mstate av) { mfastbinptr* fb; /* current fastbin being consolidated */ mfastbinptr* maxfb; /* last fastbin (for loop control) */ mchunkptr p; /* current chunk being consolidated */ mchunkptr nextp; /* next chunk to consolidate */ mchunkptr unsorted_bin; /* bin header */ mchunkptr first_unsorted; /* chunk to link to */
/* These have same use as in free() */ mchunkptr nextchunk; INTERNAL_SIZE_T size; INTERNAL_SIZE_T nextsize; INTERNAL_SIZE_T prevsize; int nextinuse;
/* Remove each chunk from fast bin and consolidate it, placing it then in unsorted bin. Among other reasons for doing this, placing in unsorted bin avoids needing to calculate actual bins until malloc is sure that chunks aren't immediately going to be reused anyway. */
maxfb = &fastbin (av, NFASTBINS - 1); fb = &fastbin (av, 0); do { p = atomic_exchange_acq (fb, NULL); if (p != 0) { do { { if (__glibc_unlikely (misaligned_chunk (p))) malloc_printerr ("malloc_consolidate(): " "unaligned fastbin chunk detected");